
Table of contents
After 1.5 years managing the Delivery team at Squarespace, it’s highlighted some things I’ve learned about CI/CD in previous jobs. If you’re out there as part of the team that manages CI/CD at your company, hopefully this advice helps you understand the practical advice to run things quickly, some cultural values that underpin what you do, and how to scale your platform.
All this info is totally anecdotal and based on my past experiences so prepare for a massive dose of survivorship bias. Be smart, compare this advice to what else is out there on the internet, and hopefully something here can inspire you to do something new! Also, this isn’t meant to be an exhaustive list of all best practises :)
Summary:
- Practicalities
- Anything that can be run in parallel, should be.
- Cache everything, including dependencies and test suite runs.
- Don’t run test suites on hyperthreaded CPU cores.
- Try running on ARM.
- Culture
- Automate your nitpicks.
- Deploy as often as you can.
- Have short feedback loops - but a CI environment is not a replacement for a good dev environment
- Scaling
- Find solutions to YAML.
- Offload non-critical tests to a periodic pipeline.
- Run nightly builds for everything.
Practicalities
When it comes to a CI system, the main interface you’re going to care about is the build configuration. This section covers practical advice for how you set up these builds, assuming speed is what you’re optimising for.
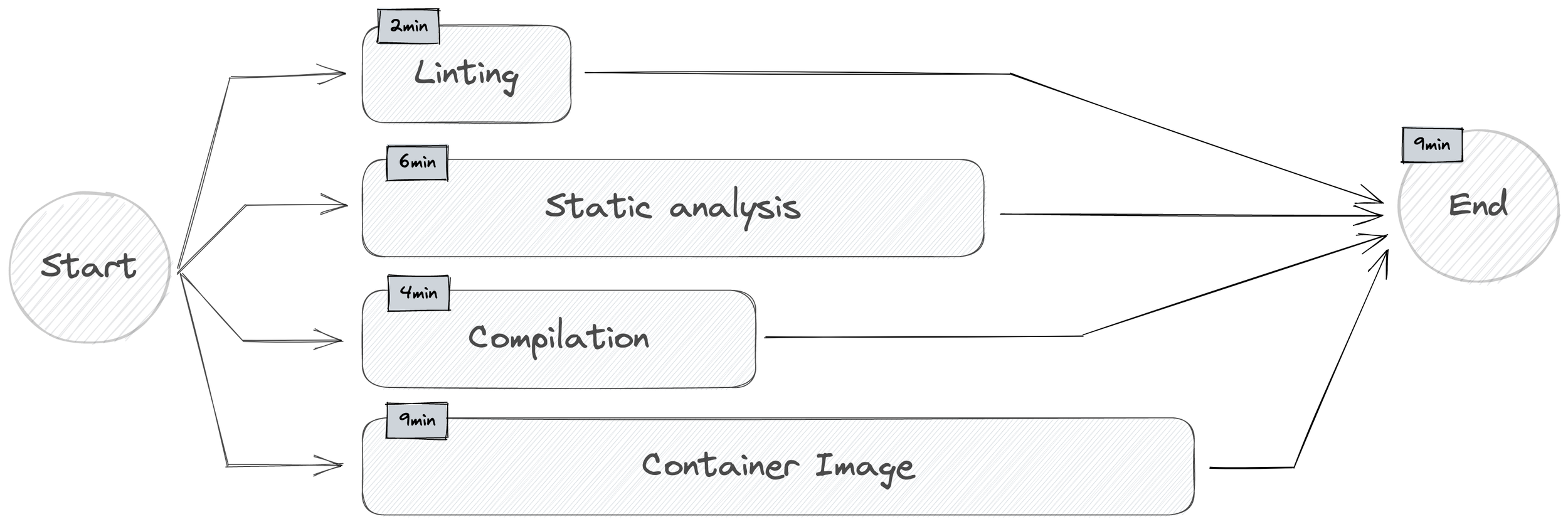
Anything that can be run in parallel, should be.
It’s a very common pattern from elsewhere in Software Engineering, but being able to parallelise your workload will mean that you are only limited by the slowest step in your pipeline.
Think deliberately about things that don’t immediately look like they could be run independently and make sure that assumption is correct. For example, if you’ve reached a scale where your test suite takes 10+ minutes, investigate whether your suite natively supports sharding those tests – or, if it doesn’t, think about how you could separate the tests manually.
Knowing your dependency graph inside-out is going to help a lot here. Here are some examples that, typically, can run in parallel:
-
Code linting
-
Static analysis
-
Binary compilation
-
Docker image build
-
Static asset uploads
-
Deploy dry runs
You can make a trade-off here to parallelise things that generate artefacts, by trading storage space for speed. Yes, if the build fails, the artefacts aren’t useful but if you can spare the storage space, and handle cleanup/archival on a fixed schedule elsewhere, you can save time by not requiring code correctness before you start building the artefacts. If the docker image build takes 5 minutes, and the full static analysis suite also takes 5 minutes, waiting for the analysis feedback before building the docker image costs you time.
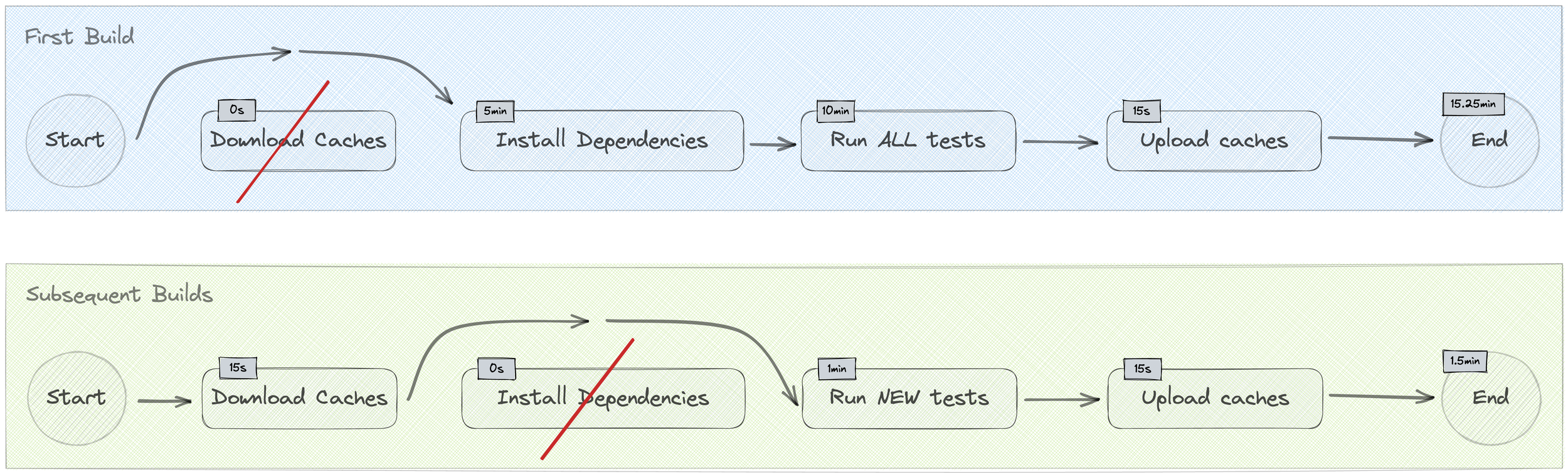
Cache everything, including dependencies and test suite runs.
In a similar vein, your builds likely rely on dependencies that don’t change very often. Things like package dependencies can be cached rather easily, and provide a considerable boost. Particularly with any NodeJS project, even basic projects can save minutes on the install step by simply caching the node_modules folder.
When using a cache, it’s important that you pick a good cache key. I’d advise that you do it based on checksums of a lock file, and a static value (like a version number “v1”). The version number lets you burst the cache in the event that something gets corrupted and uploaded. This is more of an issue if you’re using the in-built cache of a SaaS CI platform, where you don’t have the ability to burst the cache manually.
Something else that’s been a massive improvement in recent years is incremental testing. A number of test suites/unit test runners now provide a way to only run tests relevant to the code that’s changed. This requires metadata about previous build runs, and you should look into if your particular language and stack supports incremental builds/tests. For the cost of 10s to restore a cache, you could be able to save the time of 75% of your test suite on small changes. And, culturally, it may encourage smaller, incremental change.
Don’t run test suites on hyperthreaded CPU cores.
This one’s really specific but it’s come up often enough at this point that I really wish someone had mentioned it to me before, but a lot of modern test suites do auto-optimisation of resources and I’ve found that running on hyperthreaded CPU cores has majorly negatively impacted test suites for Java, NodeJS and Javascript.
If you run 8 cores, with 4 hyperthreaded, definitely run some experiments with tuning the number of workers for your suite to 4. I’ve found that it reduces the time the suite takes, but would recommend that you run directly on machines with only real cores. Hyperthreaded cores work great for varied workloads, like on servers of desktop computing, but they don’t work as well when your regular workload is consistent and uses all available CPU.
Try running on ARM.
Another recent development is the emergence of ARM-based machines. It’s still early days for me, but a lot of other folks are experiencing massive gains with test throughput and binary compilation on ARM architectures.
Try it out! Run some experiments on your longest workloads, and see if there’s a significant speed up for an easy configuration change.
Culture
You may think, like I’ve often done, that if we just use more automation, it will keep things modern and quick, but I have to draw away the curtain and reveal that driving cultural change is the only true way to keep your team sane, and your configs readable. Every day, we define how software is built and deployed through the education we provide, the patterns we follow, and the advice we evangelise.
Automate your nitpicks.
Most nitpicks are automate-able. Code style and complexity can all be handled these days by linters, and you should use them extensively. Try to think about the mundane maintenance of how you expect code to be written and enforce it through automation instead of people.
An engineer’s time is very expensive. You can minimise the amount of time they spend on repeating themselves and their team’s standards, through CI.
It also helps minimise the friction and frustration between engineers. It can get grating repeating yourself, and it can be annoying to receive a death by a thousand papercuts and small change requests.
Keeps your code consistent, and keeps folks from using up their relationship capital on minor requests.
Sidenote: Make sure your linting stack is easy to run locally as well. Pushing to CI only for it to fail on linting is fine every once in a while, but having to rely on CI to fix your subsequent linting issues gets frustrating quickly.
Deploy as often as you can.
There’s a good reason the word continuous is in Continuous Deployment. Deploying every time you merge to your mainline branch has a tonne of advantages over doing a timed release every week/month.
Firstly, it reduces the risk of any particular deployment by making debugging easier. Having one changeset to analyse makes it a lot easier to identify what’s gone wrong, and find the most appropriate person to fix it (i.e. the commit author).
Secondly, it reduces the feedback loop for changes. Folks get to see their changes go out quickly, and it makes iteration easier. The shorter the feedback loop, the easier it is to make sure your changes work with all the others.
Thirdly, everyone gets features quicker. Your customers won’t have to wait for the next release cycle, they’ll get the feature as soon as it’s ready.
Have short feedback loops - but a CI environment is not a replacement for a good dev environment
It’s important to spend some time optimising and keeping your build times lean, but don’t spend all your time doing it. There’s diminishing returns when it comes to build times. When you get to the point where you’re shaving seconds off your build, you’re unlikely to be spending your time wisely.
A short feedback loop is important. It gives people feedback quickly, allows them to iterate quicker and work faster. You don’t want folks to be that XKCD comic, but instead of “it’s compiling”, they’re shouting “it’s still building”. It’s really important that we spend the time to make this (relatively) quick to improve people’s sense of progress, and reduce the friction for writing code.
However, as important as it is, don’t fall into the trap of focusing solely on the remote CI environment. CI has an inherently longer feedback loop than local development – it gets frustrating quickly having to change a thing, commit & push, wait for the build to start, run & fail, then repeat it all until your build succeeds.
Invest just as much time into your local development environment to compensate. If you notice folks pushing excessively to the Version Control System, with increasingly duplicative or gibberish commit messages, it’s a clear sign that you need to prioritise improving the local dev environment.

Scaling
At Squarespace, we’re managing a GitHub organisation of 700 developers and 1.5k build configs. Every day, we process thousands of builds and manage all manner of variety of CI/CD pipelines – some tiny, some massive, some short, some long. When thinking about how you scale your offering, here are a couple concepts that have helped tremendously.
Find solutions to YAML.
YAML is chosen for configs everywhere because it’s got a super low barrier to entry. It’s easy to manage a small (0-100 line) YAML file, and it’s easy to read, understand and add to it.
Less so, when it’s 1,000 lines. Even less when it’s 100,000 lines (yes, I’ve seen more than one). The repetition will make your configs unmaintainable. Missing a single depends_on could lead to a whole swathe of tests getting bypassed on your production deployment. It’s not a pretty sight.
You should find a way to make your configs more maintainable. Different folks prefer different methods, so it’s very much the dealer’s choice. The traits I would recommend are:
-
Centralised management – if you’re building something that’s repeatable and reusable, keep it centrally managed to ease discoverability, encourage contributions and make large-scale change easier. If it’s a shared library, it can be as easy as a git repo.
-
Usable locally – people have to be able to test the generation of their build config locally. If you’re making a change to how configs are parsed in your system, it can’t only be possible to generate the config by submitting it for the CI server to parse; it would make it hell to debug a problem.
-
Loops, variables and functions – this one is very particular for DSLs, but all three of these features are invaluable to making your config more maintainable.
Finally, an optional but necessary piece of advice is to try and make it transparent. If someone has to run something locally to generate the config, then commit the output, it’s going to lead to some mistakes. And if you enforce that pattern with a check in CI, there’s going to be a lot of heavy sighing. It’s one of those patterns that seems fine on paper, but in practice people will not notice the custom generation and edit the wrong config to make changes. It can be particularly hostile to newcomers and onboarding.
Here are some suggestions for things that are native to various CI systems:
| Drone | Jsonnet | | GitHub Actions | Reusable workflows | | CircleCI | Reusable commands | | | Plugins via “orbs” | | | Setup / Baking Workflow | | TravisCI | Reusable config | | TeamCity | Meta Runners | | | Kotlin DSL | | Jenkins | Job DSL (Groovy |
Ultimately, we chose Jsonnet because
-
It was already in use in other parts of the company
-
It provided an easy, clean interface for us to hook a custom import into the config parser
-
Drone already had a jsonnet renderer built into its CLI
-
The syntax is close, and very similar to javascript, which is extensively used by all the product engineers in the company
Offload non-critical tests to a periodic pipeline.
There’s a simple way to speed up testing: run less tests.
The likelihood that you’re going to get people on board with straight up deleting tests is lower than low. Instead, what I’d recommend is having folks sit down and understand what is the critical path through the application, and focus your tests there. Particularly with overly-sensitive or flaky tests, relegate them out of the critical path and focus entirely on the things that the business considers central to its existence.
Now you have two categories of tests:
-
Blocking, critical path tests – these should cause build failures and are required for any code to go to production
-
Non-blocking tests – these are not required for code to go to prod
Instead of just discarding those non-blocking tests, instead put them in a pipeline all on their own. One that’s going to run hourly/daily/weekly, and still highlight regressions and issues with our code.
Separating the tests lets you build a culture around what’s important to care about, and what’s a non-blocker to getting your code out into the wild. It can also speed up your pipeline significantly. Particularly around UI tests, which often rely on timeouts to know if they’ve failed. Waiting for those 20-30s timeouts adds up, quickly.
This is also a good exercise for things like instrumenting better observability, prioritising reliability and understanding the core of the business. Regardless of scale, any company older than a year should have a clear idea of the critical path through its service, and what that looks like in the code.
Run nightly builds for everything.
Get in the habit of running your builds nightly and alerting on failures. Old code rots and you don’t want to debug a pipeline in an incident. Ensure that your code builds, and invest the incremental time to deal with issues, rather than trying to fix it urgently when there’s more at stake.
One of the benefits here is that it will highlight systemic issues with your builds in batches, so that you can deal with them all in one go. The base images you choose will eventually experience expired GPG keys, outdated system packages, updates to unpinned dependencies, etc. etc. It’s good to experience the same failure all at the same time, especially when you can choose to deal with it in your own time.
This doesn’t mean do a nightly deploy – we don’t want to wake someone up in the night. Run your pipeline in dry run mode because we’re not testing the correctness of the business logic here, we’re testing the functionality of the build pipeline itself. We should run the build as if it were the real thing, but not actually deploy or send the artefacts anywhere.
