Table of contents
What is this document?
This document is about the theory of incident response, it is not a prescription for how to do incident response necessarily. Its aim is to familiarise yourself with the lifecycle of an incident and give you general advice. If you are not the Incident Commander (IC) for an incident, the information in this document is still useful, to understand the current priorities of the incident, what can be done to help and to hold the IC accountable.
Thank you to Fran Garcia, and my team at the time, for teaching me how to do incidents The Right Way 💖
Why Structured Incident Response?
In their natural habitat, a group of engineers in the wild will pounce on an unsuspecting incident and solve it mercilessly. They will zero in on the relevant technical issues and address them until the incident is gone. Unfortunately, while it might feel that jumping straight into the technical details is the most efficient way to handle an incident, this is not necessarily the case when we need to involve external customers.
We want to have a clearly defined and effective incident management process to avoid (among others) the following pitfalls:
-
We step on each other’s toes when making changes. For example, Casey decides to restart the drone agents without telling anybody while Morgan is doing the same.
-
We don’t communicate timely details of the incident to our customers.
-
We have different people/teams demanding to be updated on the incident progress while we’re trying to work hard on addressing the actual issues.
-
Two hours into the incident, nobody has a clear idea of what the customer impact (if any) actually is.
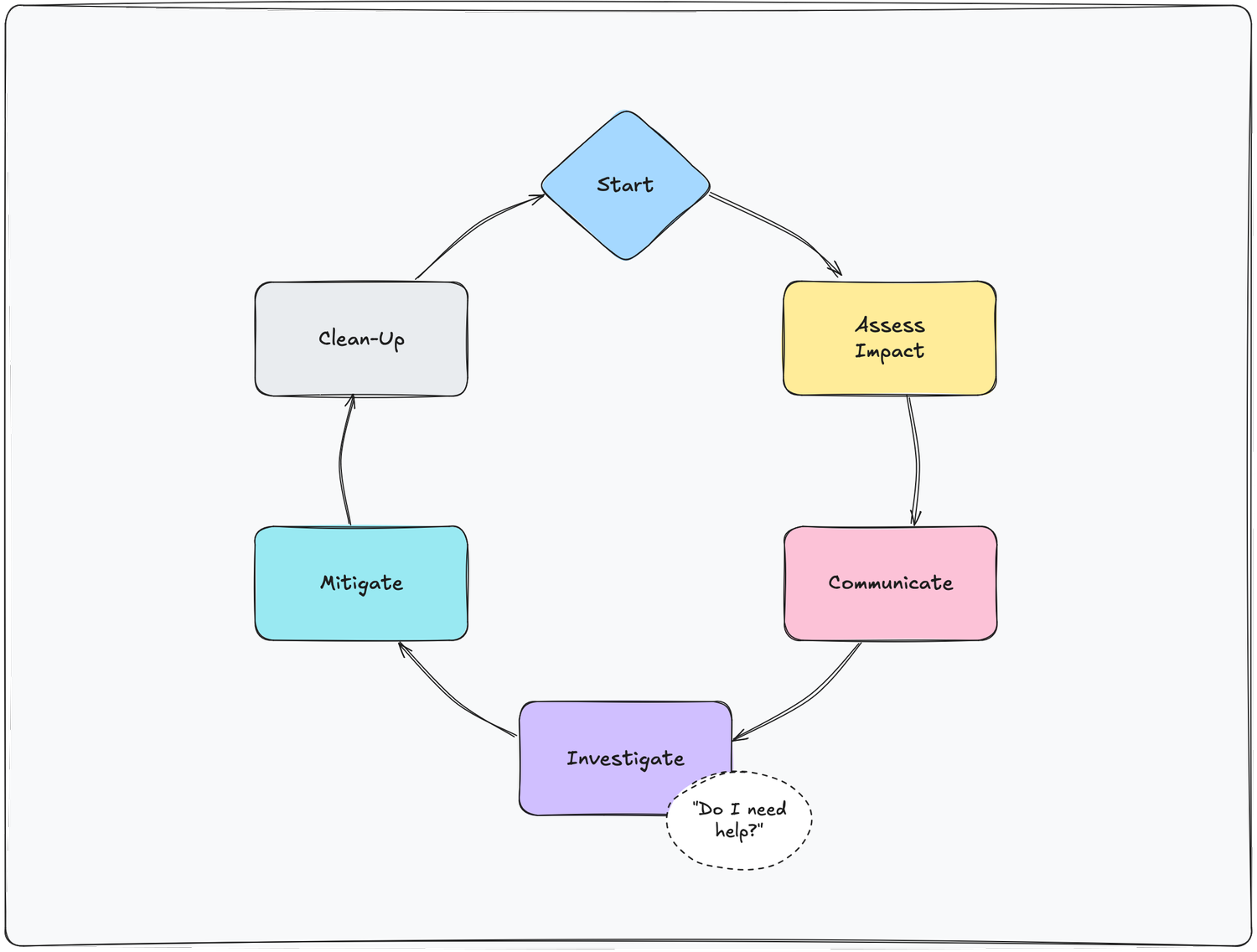
The Incident Response Lifecycle
-
The Start: An incident is born.
-
Assess Impact: Assess the impact of the incident and what/who it affects.
-
Communicate: Do we need to update our customers?
-
Intermission: Do I need more people? Do I need help? -
Investigate: Get more info, try to figure out what’s going on.
-
Mitigate: Ease the impact of the incident.
-
Clean-Up: After the issue has been mitigated, we should do some follow-up work.
Quick note: Investigation and mitigation can often happen in parallel depending on how much we already know about an incident from our impact assessment.
In The Beginning
Not all incidents initially manifest themselves the same way. You’ll first learn about some incidents when your phone starts to ring in the middle of the night and the notifications don’t stop popping up for five more minutes after you have acknowledged everything, while other incidents present themselves as someone muttering “huh, that’s funny” when working on something completely unrelated.
This means that sometimes it’s not quite obvious when we are in incident mode and when we aren’t. For this reason, whenever we’re troubleshooting something affecting our services it’s worth asking yourself “hold on a second, is this an incident?”. Doing so will allow us to start drawing on our experience of incident management and get the actual process started, so it’s a good idea to try to identify it as soon as possible.
What exactly is an incident anyway? There’s no clear-cut rule for when to actually declare an incident, but there are two rules of thumb that can help cover the vast majority of cases:
-
An incident is whenever the oncall person says there is one.
-
An incident is any new or recurrent disruption of degradation of service that either impacts or risks impacting our customers if left unchecked.
Assess
Assessing the impact of an incident is going to vary from one incident to the next, so it’s mostly left as an exercise for you, dear reader. However, there are some general questions we can ask ourselves to gauge the impact:
-
Who is affected by this? Is it just one customer, all of them, 20% of them?
-
What’s the actual impact of the service failure? Are we failing to run builds? Would it go unnoticed in most scenarios? This will be important for communicating with our customers.
-
Do we know when the issue started? Often, the issue start time is not the same as the time we were made aware of it.
Remember that this is a preliminary step, so we can’t spend much time on it, we don’t need to be accurate, but even just having a rough estimate is important.
For most incidents this initial step should ideally be capped at less than 5 minutes: while we’re still assessing the incident we should value speed over accuracy. We’ll have time to revisit this while the incident is ongoing.
Communicate
Now that we know the impact, we probably have a good idea on who is affected and how badly. We should communicate the impact to our customers as clearly as possible. If you’d like some help with what to say and how to say it, check out Communication During Incidents.
Intermission (Do I Need Help?)
If, at any point, or even during, the initial impact assessment, day or night, you feel any of the following, it may be a sign that you need to bring one or more people onboard to help with the incident.
-
I’m not sure what’s wrong
-
I’m not sure how to fix it
-
I don’t know if we can fix it
-
I don’t know if I can deal with this
-
I don’t think I have the capacity to deal with this
That’s fine! None of us are expected to be able to handle every single incident on our own without any help, that’s why we’re a team.
Investigate
Ideally, the alert that paged you has enough information for you to understand where the pain is and how to better look at it. If it hasn’t, that’s a good follow-up task for the last stage of the lifecycle.
Here are some notes that are usually useful:
-
Breathe and make sure you think every step through. We want to be able to reason through each step we take. Solving an incident should be a sequence of logical steps, not a bunch of blind actions in hopes that one sticks.
-
What has changed? Have we changed something recently that could impact this service in a similar manner? This is where knowing when the incident started comes in handy, as it allows you to quickly check through our commit history or check a third-party status page for incidents.
-
What do the metrics show? Do we have a grafana dashboard for this service?
-
Anything on the logs stands out? Remember, if we see a stream of errors coming from a particular service it’s worth going all the way back to the first instance, in case it was triggered by the existence of a different error.
Mitigate
Mitigate is the word of the hour here. It is perfectly natural to see the impact and know how to fix it for good, but often that fix would take a lot longer than the bandaid we really want in this situation. It’s important that we stem the bleeding before attending to the patient.
Our main goal during an incident is not necessarily to identify the cause(s) or to push a complete fix, but to mitigate customer impact as soon as possible so we can continue investigating and working on a permanent fix without the extra pressure of ongoing customer impact.
The simplest solution is best, we can schedule long-term fixes later. For example, we should always roll back (go back to a stable state) and rarely roll forward (commit a hotpatch/fix).
While we’re doing this, it’s also important to collect as much information as we can to help with any further investigation: maybe there were some particularly spicy error messages you noticed, or you could keep one server untouched so more debugging can be done.
Clean-Up
Every incident that we get paged for should ideally have at least one followup task associated with it. Remember that we don’t ever want to deal with the same incident twice, which means we need to do something better the next time, like automating our response to it, improving our monitoring, adding redundancy, figure out which team created the error and get them to figure out how to fix it so it doesn’t happen again, etc… Additionally, maybe while troubleshooting you’ve seen an application that logs too much, making it difficult to dig through the logs, or maybe you’ve seen an error message that is a bit suspicious, so you’ll want to create tasks to look at those as well (this might help prevent a brand new incident next week!)
-
If late, gather a timeline and collect information for investigation in the morning.
-
We should investigate this issue further to create tickets for the factors that caused it.
Note-Taking And Communication In Slack
One of the most important things you can do is take notes of what’s going on. You don’t need a high level of detail, but keeping a record of some of the important things that are happening will certainly prove invaluable in the future.
One of the best ways to ensure we keep a record of what’s going on during an incident is to do as much of our incident management as possible within Slack. The best way to achieve this is to have most of our incident-related conversations within Slack and explicitly calling out every action/role change that’s taking place. For example, if Alex is going to be in charge of communications for this incident it’s explicitly called out (“@alex is doing communications now”), or if we have decided to flush the cache in a given service (“flushing the cache for the frobnicator service now”) we give a heads up so people are aware of what’s going on and we have a nice log of all actions/decisions along with timestamps to be used when constructing a timeline for this incident.
Even if most of the conversation is happening in person, it’s worth summarising the decisions taken to Slack both for making sure everybody else is in the loop and to keep a log of events. Remember, sometimes the decisions or actions we take are not as important as the information that we used to get to that point or the tradeoffs we were willing to make at the time, so whenever possible always state the information you’re basing your decisions on, and if you’re knowingly making a tradeoff state it explicitly (“clearing the cache will affect image pull times but it will give us a better shot at resolving the incident sooner, so we’re going to do that”). This will be very useful when the time to review the incident comes and we can revisit every step we took in its original context, as opposed to revisiting every single decision from the safety and comfort of hindsight.
Further Reading
-
“Managing Incidents” from Chapter 14 of The SRE Book
-
“Incidents As We Imagine Them Versus How They Actually Are” by John Allspaw (video)
-
“How Complex Systems Fail” by Richard Cook
-
“Good EMTs Don’t Run” by Dan White