
Table of contents
Every system always operates at its capacity. As soon as there is some improvement, some new technology, we stretch it.
— Larry Hirschorn, “A Tale of Two Stories: Contrasting Views of Patient Safety” by Woods & Cook, 1997
Why do complex systems fail?
In the last 100 years, there’s been a lot of intense and distributed advancement in technology, and our use of it as a species. As technology advanced, it also brought catastrophic and costly failure. There’s a lot to be learned about the theory behind failure, safety and resiliency, on the back of the events of the 20th century.
To understand why failure happens, a popular and still-relevant model is the “Rasmussen Migration Model” (1997) which tries to describe the forces/pressures acting on a system, and influences the system to “drift into danger”. It’s well regarded within the Resilience Engineering and Safety Culture areas of research.
Smarter people than me explain this much better, but I’m going to try and do my best to talk about it in my own words for the sake of a complete story in this post.
Other, fabulous explanations are:
-
https://youtu.be/PGLYEDpNu60?si=19MlY-xaQBts97VH (20 min watch)
-
https://risk-engineering.org/concept/Rasmussen-practical-drift (30 min read)
What is a System? And what are our constraints?
We can think of our System’s current state as an “operating point” that moves randomly and erratically inside the full space of possibility allowed to it. Importantly, our System is not just our software, infrastructure or technological systems, it also includes the people who build, maintain and operate those systems. The complex system we run is more than just the code we write, it is the people we are. For the sake of this whole post, the limit of our System is Product Engineering.
If we took all humans and non-software factors out of the equation, you could think of the Operating Point as our software working efficiently, correctly and profitably. It’s not throwing exceptions. It’s not crashing out. And it’s not overwhelmed. The Operating Point is “within parameters”.
But our systems don’t exist in a vacuum, and we have boundaries and constraints that we want to avoid as best we can:
-
Economic failure: Our system is not profitable enough, or is too costly and inefficient to be funded to run.
-
Unacceptable workload: The burden on our people and technology is too large to continue.
-
Acceptable performance: We take too many risks, and accidents occur.
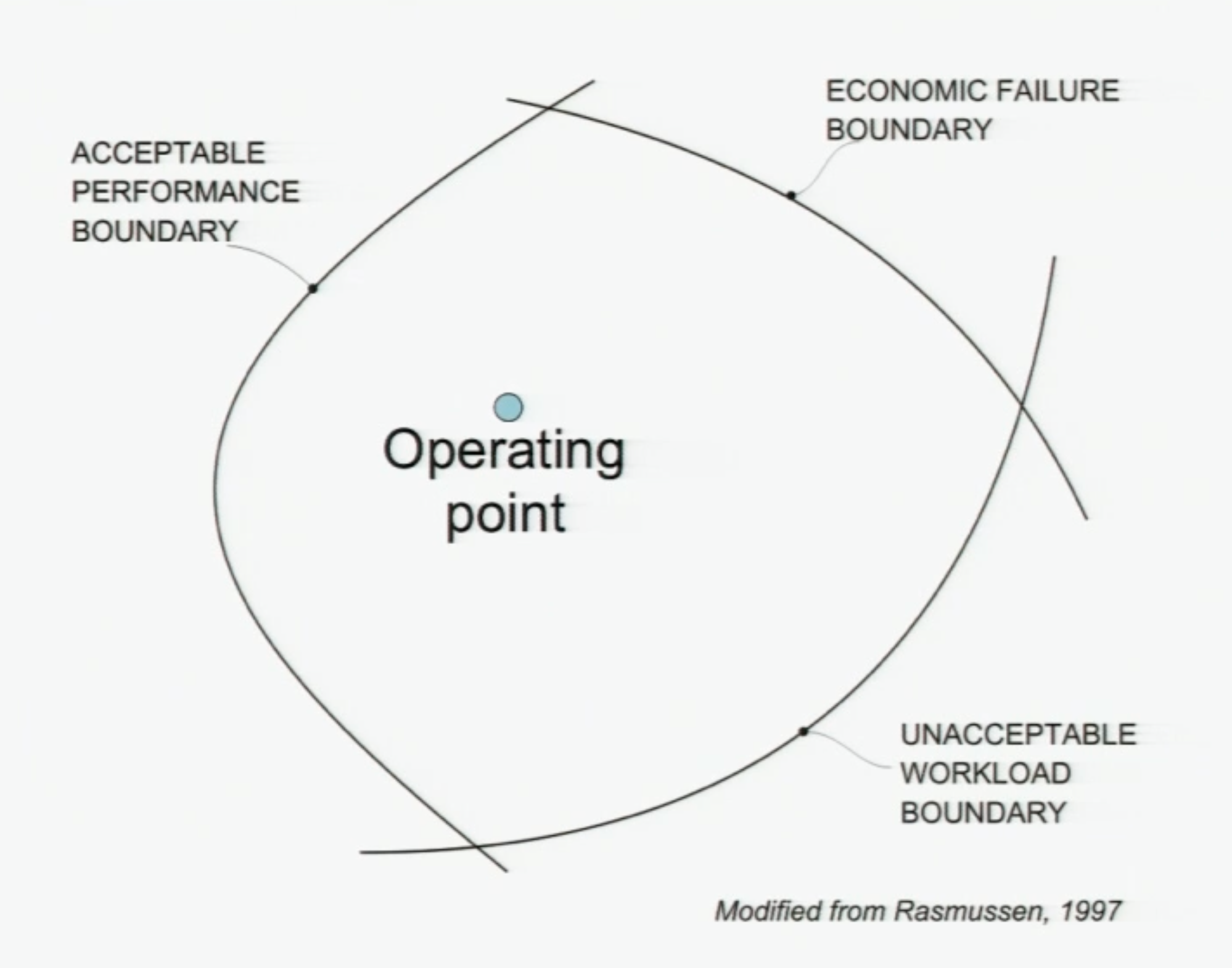

Easy fix: Just stay in the middle.
There are two reasons why we can’t look at this model, digest it and decide point-blank to stay in the middle:
-
You’ll have noticed how heavily theoretical this model is. It’s hard to define these boundaries in concrete, measurable terms. And even harder to quantify the current state of the Operating Point because it “moves randomly and erratically” (like brownian motion) even when no force is acting on it.
-
There is always some kind of force acting on it. Our System is influenced by people, society and other complex systems. We cannot escape external influence.
Below I’ve stolen an example of two forces on our Operating Point from one of the sources I mentioned above:

The competitive environment encourages decision-makers to focus on short-term financial success and survival, rather than on long-term criteria (including safety).

Workers will seek to maximise the efficiency of their work, with a gradient in the direction of reduced workload (in particular if they are encouraged by a “cheaper, faster, better” organisational goal).
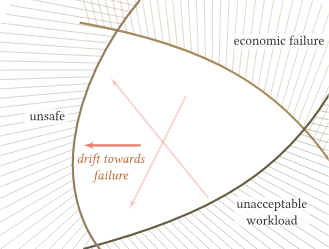
These pressures push work to migrate towards the limits of acceptable (safe) performance. Accidents occur when the system’s activity crosses the boundary into unacceptable safety.
The example uses two competing forces: pressure for financial success and the pressure to reduce employee workload. It is important to highlight that this model does not include any moral judgements. This drift towards failure is not caused by any particular group’s intent to create an incident, or cause an accident. It is a byproduct of our innate human nature to adapt to our environment, its constraints, and our instructions.
What does this look like in reality?
I like the idea of the Gamma Knife Model as an analogy for how this all works in practice. So I’m going to rob it wholesale from the person who wrote it: Lorin Hochstein The Gamma Knife model of incidents
Gamma knife (https://en.wikipedia.org/wiki/Radiosurgery#Gamma_Knife) is a system that surgeons use for treating brain tumors by focusing multiple beams of gamma radiation on a small volume inside of the brain.
Each individual beam is of low enough intensity that it doesn’t affect brain tissue. It is only when multiple beams intersect at one point that the combined intensity of the radiation has an impact.
Every day inside of your system, there are things that are happening (or not happening(!)) that could potentially enable an incident. You can think of each of these as a low-level beam of gamma radiation going off in a random direction. Somebody pushes a change to production, zap! Somebody makes a configuration change with a typo, zap! Somebody goes on vacation, zap! There’s an on-call shift change, zap! A particular service hasn’t been deployed in weeks, zap!
Most of these zaps are harmless, they have no observable impact on the health of the overall system. Sometimes, though, many of these zaps will happen to go off at the same time and all point to the same location. When that happens, boom, you have an incident on your hands.
Why DON’T complex systems fail?
What is surprising in this world is not that there are so many accidents, it is that there are so few. [Software engineers] know this to be true. The thing that amazes you is not that your system goes down sometimes, but that it is up at all.
— Richard Cook, “Resilience In Complex Adaptive Systems”
An undeniable fact is that not every complex system over the last century has gone up in flames and reset our progress in society to zero, so what can we do to make our systems more resilient to failure when it happens?
The main four categories, at least according to folks like Richard Cook and John Allspaw, are:
-
Monitoring: For software, we immediately think of observability for our running technology, but this also includes employee surveys, tracking workloads and caring for people, technology and the company altogether.
-
Reacting: Incident response, mitigating issues, applying bug fixes, scheduling PTO, transparency around planning/decisions, direct communication, etc.
-
Anticipating: Preventative care, which can look a lot like the above list. Other examples are design documents, long-term vision/design planning, documenting priorities and tradeoffs, timeline warnings about changes and workload increases.
-
Learning: When something does go wrong, how do we understand and analyse it?
Learning is the one I want to focus on for the rest of this post.
Learning: Understanding failure
There is no root cause
I’m hoping that from the above, there is already a thought percolating in your noggin, but to be explicit about it: Every incident is a collection of cascading failures, there is no Root Cause.
As an engineer, you might immediately balk at that statement. Our job is to boil down complex problems into simple, solvable chunks. We want there to be a root cause, because if we can fix that bug, we can solve the incident and prevent that issue from happening again… right?
We saw in the Rasmussen Model that the drift towards danger, and incidents, is caused by the natural adaptive forces of The Universe™️. We should instead view the causes as a game of Buckaroo, and the latest, most apparent cause, as the straw that finally broke the camel’s back.
From John Allspaw Kitchen Soap – Each necessary, but only jointly sufficient:
Regardless of the implementation, most systemic models recognize these things:
• …that complex systems involve not only technology but organizational (social, cultural) influences, and those deserve equal (if not more) attention in investigation
• …that fundamentally surprising results come from behaviors that are emergent. This means they can and do come from components interacting in ways that cannot be predicted.
• …that nonlinear behaviors should be expected. A small perturbation can result in catastrophically large and cascading failures.
• …human performance and variability are not intrinsically coupled with causes. Terms like “situational awareness” and “crew resource management” are blunt concepts that can mask the reasons why it made sense for someone to act in a way that they did with regards to a contributing cause of a failure.
• …diversity of components and complexity in a system can augment the resilience of a system, not simply bring about vulnerabilities.
In reducing the factors of an incident down to singular root cause, we are doing a disservice to our own ability to prevent more failure in the future, and we are polluting our learning with Hindsight Bias that leaves us with a document preserving only one chain of “Why”s in a sea of other questions.
Having a root cause also reduces the incident’s accountability down to the person who made that error, which moves us from attributing a single factor to a person to blaming that person for what happened overall.
Blame vs Attribution
I think, and correct me if I’m wrong, people intuitively understand why the reflection on failure should be blameless. Our empathy for each other means we don’t want people to shoulder the unearned burden of feeling like they single-handedly caused an outage or a problem and dragged us from our slumber at 4AM for a 16-hour-long day. Partly, because it’s never singly their fault.
That being said, being blameless does not mean that we cannot know who performed an action, who made an error, who did something they shouldn’t have at an inopportune time. It is important we have the ability to interview that person and get to ask questions about their goals, assumptions, motivations and thought process throughout.
We achieve these by both reinforcing the idea that that an incident is caused by many different failures, and that no action taken innocently without malice should result in punishment. Yes, you hit the big red button that took down prod, but we want to know why you did it, what assumptions you made and what your goal was with pushing it. And the important bit is that we knew and acknowledge you did it. Otherwise, how would we get to learn from any of this. We’d just be ignoring the elephant in the room.
Everyone should feel psychologically, and financially, safe to put their hand up and admit that they made a mistake. And the response should be an enthusiastic thank you.
Excerpt from IT Revolution The Andon Cord:
A second important cultural aspect of the “Andon Cord” process at Toyota was that when the team leader arrived at the workstation, he or she thanked the team member who pulled the Cord. This was another unconditional behavior reinforcement. The repetition of this simple gesture formed a learning pattern of what we call today “Safety Culture”. The team member did not, or would never be, in a position of feeling fear or retribution for stopping the line.
Quite the contrary, the team member was always rewarded verbally. What Toyota was saying to the team member was “We thank you and your CEO thanks you. You have saved a customer from receiving a defect.” Moreover, they were saying, “You have given us (Toyota) an opportunity to learn and for that we really thank you.
Anticipating failure is hard
We do not have a company-expensed crystal scrying orb mounted to the walls of our Cork office, and we cannot pore over it every Monday at our team meeting to see what the week will hold. As much as we try, we cannot predict the future. And this holds true for the tests we write, the verification steps we take, or the risk assessments we write.
If you can foresee a problem that is easy to address now, you should absolutely do it. This is not some Nietzsche-esque call to “nothing matters, so why bother”. Instead, I want us to collectively acknowledge that no matter how much we plan and prepare for failure, we will never exist in a reality where it does not happen. I would go even further and say that not only will failure happen, it will happen often.
We are building software under the pressure of economics, and that requires us to push the boundaries and capacity of technology to run leaner, run faster, and run at scale. Even if the pressures aren’t explicit, they are implicit in running a successful business that keeps us all employed.
Instead, we should always strive to be explicit and communicative when we’re taking risk, and we should be at peace that failure will happen.
Failure is good, actually
Every incident we retro, every bug we fix, every document we write, is another brick in the foundation of our resilience. As we encounter and respond to failure, we add a force to the Rasmussen model that pushes our Operating Point us further away from the unsafe boundary and gives us more room to innovate, take risks, and improve upon what we have.
There are practical mechanisms for managing and quantifying the amount of failure we’re comfortable with as a company, but this isn’t the place to list them. What’s important is that we embrace failure as the best learning opportunity we’ll get.
Excerpt from IT Revolution The Andon Cord
There is a great story in the Toyota Kata book where at one point a particular Toyota plant notices that the average Andon Cord pulls in a shift goes down from 1000 to 700. As Rother describes most western culture organizations would break out the champagne for such an occasion, not Toyota. The CEO called an all-hands meeting to address the “problem”.
Notice I said problem.
The CEO then goes on to describe that “we” must have one of two problems here. One, we are getting lazy and letting more defects get through the system or two, if that is not the case, then we are not operating at our full potential. He was telling everyone that if they were staffed to handle 1000 pulls per shift, then they should be pulling a 1000 Cords per shift.
In plain words, the CEO is saying more pulls equals more learning which means more improvement that gets us towards our vision. 1X1 was a means to an end to say “If we can produce cars faster, cheaper and with higher quality, we win.
In Conclusion
Incidents are caused by a collection of, often emergent and unpredictable, behaviours in both our systems and our people that we should not aim to condense or shy away from. Doing so:
-
Convinces us our systems are safer than they are.
-
Leads to a poorer understanding of our systems.
-
Concentrates blame.
-
Revises history after the fact with Hindsight Bias.
-
Robs us of the chance to push ourselves further from the unsafe boundary.
Further reading
I’ve mentioned most of these, but Resilience Engineering is a massive academic area of study, so I figured I could curate some things that are probably the most relevant to us.
Building resilient software/culture
The theory of graceful extensibility - basic rules that govern adaptive systems.pdf
https://ferd.ca/complexity-has-to-live-somewhere.html
https://itrevolution.com/kata/
Understanding failure and safety
https://how.complexsystems.fail/
https://risk-engineering.org/concept/Rasmussen-practical-drift
https://surfingcomplexity.blog/2019/08/25/the-gamma-knife-model-of-incidents/
https://www.kitchensoap.com/2014/11/14/the-infinite-hows-or-the-dangers-of-the-five-whys/
https://www.kitchensoap.com/2012/02/10/each-necessary-but-only-jointly-sufficient/