Table of contents
Risks of LLMs in the SDLC
Everywhere I look in the software engineering space, I’m seeing very similar vibes as LLMs are increasing the pace at which people churn out changes. With that pace change, I’m also wary of just how much risk there is to introducing more of the non-deterministic water-chugging blackbox magic machine.
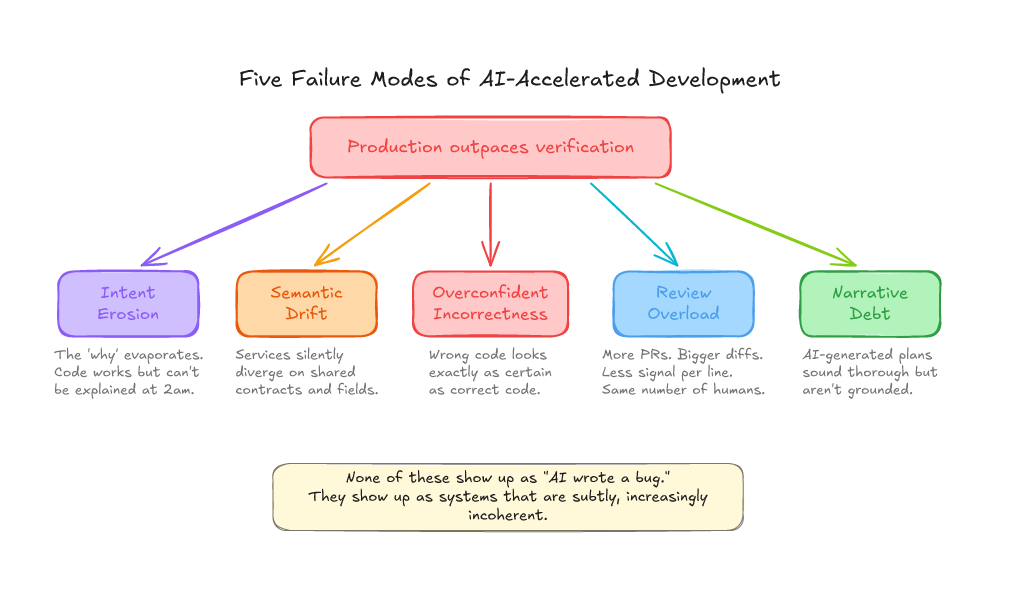
It’s very appealing to business to want to go quicker, faster, and more lean by YOLOing the LLM code generation, and deferring the consequences. LLMs aren’t necessarily creating these risks, but they’re amplifying them a thousandfold. To me, there are 5 clear risks:
- Intent Erosion: As time goes on, the system accumulates behaviour that is hard to reason about. You’re asking yourself more and more: “wait… why did we choose to do this again?”.
- Semantic Drift: Your services and code evolve in inconsistent ways, and shared conventions diverge.
- Overconfident Incorrectness: You know, you love it, you’re Absolutely Right about it, the output from an LLM seems so certain about what it just said, and it’s totally bogus to the trained eye.
- Security Regression: There’s been a lot of research in this area, and LLM-generated code is not immune to regurgitating security holes.
- Actuation Bandwidth: As the speed of generated text increases, more and more pressure is put on the evergreen bottleneck of a software team: code review. A big risk here is a long tail of costly iterative review loops eating smart people’s time.
Intent is eroding, and you won’t notice until it becomes an incident
This is the one I worry about most.
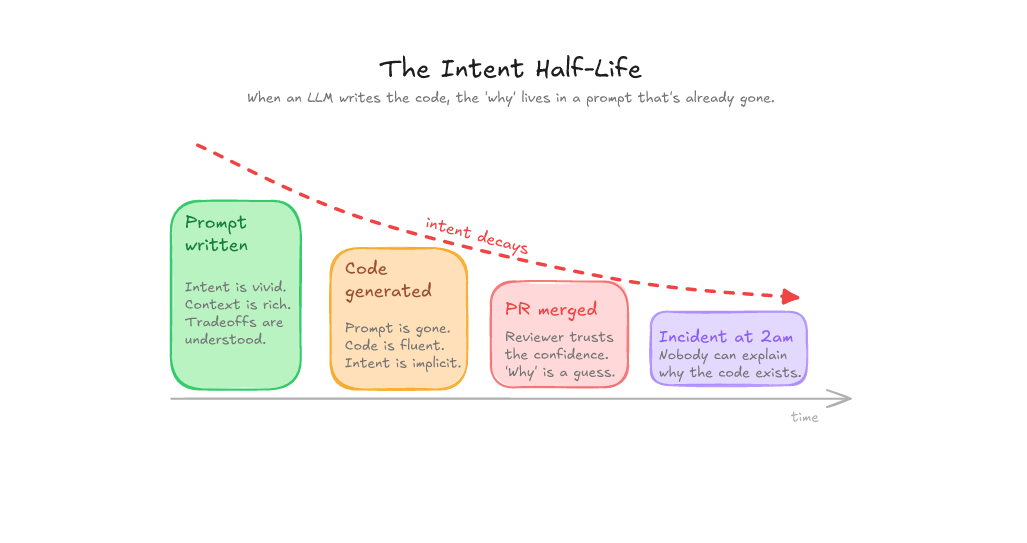
When an engineer writes code from scratch, the “why” lives in their head during implementation and leaks into commit messages, PR descriptions, and code structure - imperfectly, but the artifacts of human understanding are there. You can feel where someone was uncertain. You can see the TODO comments, the overly-cautious error handling, the variable names that betray what they were actually thinking about.
When an LLM generates code, the “why” was in the prompt. The prompt is gone. You’re left with clean, plausible code and nobody wrote down why it exists. Six weeks later, during an incident at 4am, you’re staring at a service that does something and nobody can explain the reasoning behind it.
This compounds. System after system accumulates behaviour that is functional but unexplainable. Intent reconstruction becomes the bottleneck in every incident. You stop understanding your own software; not because it’s poorly written, but because the decision trail evaporated.
Richard Cook wrote about how complex systems fail, and one of the things that stuck with me is that failures usually come from the gap between what the system does and what people think it does. LLMs just make that gap grow faster.
Semantic drift accelerates silently
An LLM makes it trivially easy to “just add a field,” “just add a retry,” “just add a transformation.” Each change makes sense on its own. Zoom out and it’s entropy.
One service starts treating a timestamp as UTC. Another assumes local time. A shared field means “user ID” in one context and “account ID” in another. Retry semantics diverge. Error taxonomies drift. None of these show up in type checking. They show up as integration failures in production — the kind where every service is “working correctly” and the system is broken.
This was always a risk, but the rate of change was a natural brake. When it takes effort to make changes, you’re more likely to check the contract, read the existing code, and ask a teammate. When an LLM produces a change in seconds, that friction vanishes. And with it, the accidental coordination that kept your services coherent.
I wrote about splitting up API-breaking changes years ago, and the core idea was that you need to be deliberate about how contracts evolve. An LLM is basically the opposite of deliberate. It’s fast, confident, and couldn’t tell you what contract it agreed to last week if you asked.
Overconfidence is the default, not the exception
LLMs don’t hedge. They don’t say “I’m not sure about the retry semantics here” or “this might conflict with how the downstream service handles nulls.” They produce wrong code that reads exactly like correct code.
This means your review process (which was designed for human-authored code where uncertainty is often visible in style, comments, or questions) is now facing a stream of changes that all look equally confident. Reviewers can’t distinguish “the author understood this deeply” from “the LLM generated something plausible” without doing a full independent analysis of every change.
The research backs this up. A Stanford study found that developers using AI assistants produced code with more security vulnerabilities while simultaneously being more confident that their code was secure. LLMs aren’t bad at coding — they’re just optimising for “sounds right” over “is right”. And when those two diverge, the model has no idea.
This is where the Security Regression risk lives too. The same study found that access to an AI assistant made participants more likely to introduce security vulnerabilities. The model has no concept of “works safely” as distinct from “works”, and if you trust the output, neither do you.
Your verification capacity is now the bottleneck
Here’s the thing: LLMs increase how fast you can produce candidate changes. Tests, review, observability, operational understanding. None of those got faster.
You’ve pointed a firehose at a funnel and you’re wondering why the floor is wet.
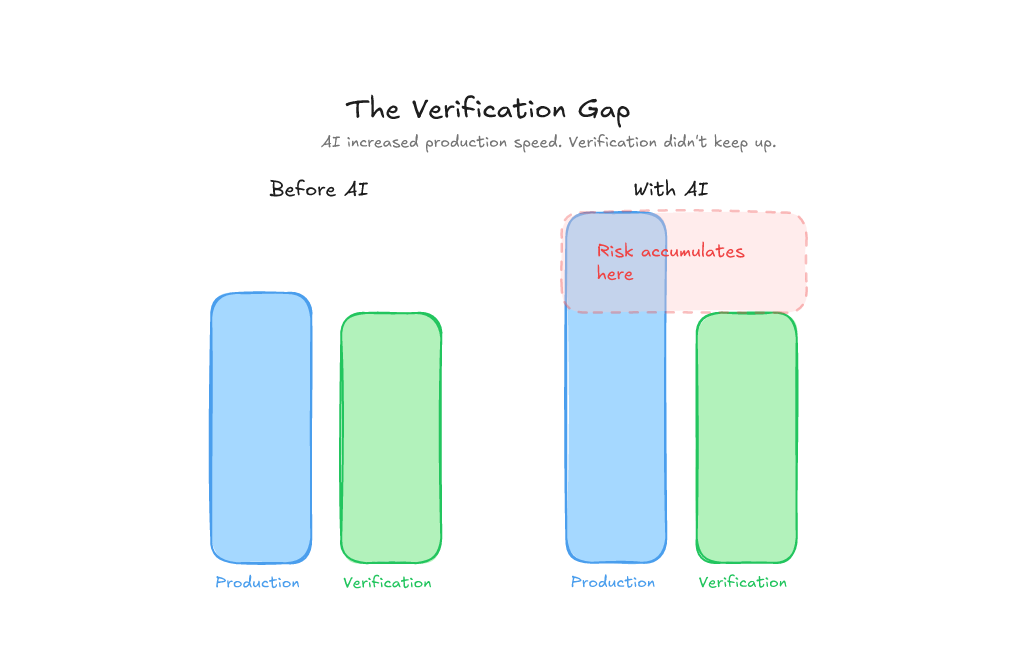
I think of it like the Rasmussen Migration Model: there’s a natural drift towards the unsafe boundary, and LLMs have basically kicked the brakes off.
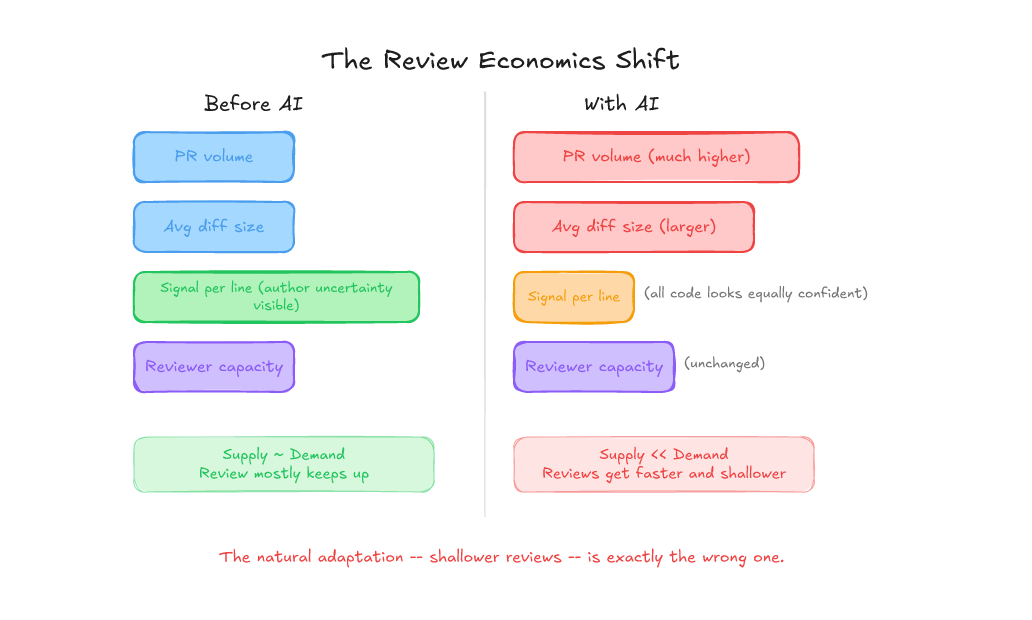
If your reviewers feel overwhelmed, it’s not because they’re not trying hard enough. It’s because the economics of review have changed. Telling people to “review more carefully” is about as useful as telling people to “just be more careful” after an incident. And we know how well that works.
You’re getting more PRs, with bigger diffs, and each line of diff tells you less about what the author was thinking — because the author was an LLM and it wasn’t thinking anything.
More PRs. Bigger diffs. Less signal per line. Same number of reviewers. That’s not a discipline problem. That’s a structural mismatch. And the natural response (faster, shallower reviews) is exactly the wrong adaptation, because the changes that most need deep review are now harder to distinguish from the ones that don’t.
Some recent research on agent-authored PRs confirms this: while many merge quickly, a long tail triggers expensive iterative review loops. The distribution has fat tails, and your review process probably wasn’t designed for that.
The planning layer gets contaminated too
LLM-assisted discovery and planning produce beautiful documents that can be confidently, comprehensively wrong. An LLM will draft a technical plan that reads like it was written by a senior engineer: architecture diagrams, risk assessments, and success criteria. It feels thorough. But it’s writing a story, not checking the facts. It can’t feel the operational reality of your system. It doesn’t know that the service it’s proposing to depend on falls over under load every Thursday, or that the “simple schema change” actually requires a multi-phase migration because of how your analytics pipeline works.
The result is “narrative debt”: polished plans that look ready but aren’t grounded in reality. They cost more to unwind than a rough plan that was honest about unknowns — because the team trusted the polish. It’s the planning equivalent of someone confidently giving you directions to a place they’ve never been.
The uncomfortable truth
As the industry leans further and further into the LLM rabbit-hole, we’re experiencing stress on the bits we’ve always been bad at: optimising the human in our development loop.
All of the above are not new because LLMs exist. Humans produce insecure code. Humans defy standards and conventions. Humans overrepresent faulty solutions in a confident voice. What has changed is that 1) we’re experiencing the flawed integration points faster and more often; and 2) while a human will, hopefully, learn over time from their mistakes, an LLM is a chain of ephemeral sessions with thousands of “memory solutions” promising to solve that problem.
Before you accelerate further into the promised lands of Fully Automated Luxury Space Capitalism, you should be prepared to confront the failings of your humanity now more than ever.
Further reading
- “How Complex Systems Fail” by Richard Cook — if you read one thing on this list, make it this one
- Rasmussen’s Risk Management Framework — how systems drift towards danger without anyone noticing
- “Do Users Write More Insecure Code with AI Assistants?” — the Stanford study I referenced above
- “Large-Scale Study of AI Agent-Authored PRs” — the fat tails of agent-generated code review
- Splitting Up API-Breaking Changes — my earlier post on deliberate contract evolution